众所周知,前端的内容一般都是通过 HTTP 相关协议获取,并在浏览器上呈现的
要想深刻了解浏览器的请求机制,首先要有一定的 计算机网络基础
浏览器的请求流程
显然,我们要先了解一下,当我们访问一个网页时,浏览器都做了什么
浏览器执行了以下动作
- URL 解析,判断用户输入的是什么,自动组装请求
- 查看本地缓存,是否有已经缓存的该地址的资源,若未过期则直接取用,跳到处理 HTML 文档
- DNS 查询,获得服务器地址
- 与服务器建立 TCP 连接,如果是 HTTPS 协议,还会有密钥交换
- 向服务器发送 HTTP 或 HTTPS 请求
- 服务器如果回复了一个永久重定向(301)或临时重定向(302),则浏览器需要向新的地址重新发送请求
- 服务器处理请求并响应,此时浏览器收到的响应状态码可能是 200 或 304
- 浏览器开始处理 HTML 文档,根据 HTML 文档生成 DOM 树和 CSSOM 树
- 合并两棵树,得到渲染树
- 根据渲染树,开始执行渲染五步骤
总的来说,涉及以下知识点
- 缓存机制
- DNS 查询
- TCP 连接
- HTTP 与 HTTPS
- 页面渲染
缓存机制
显然网络请求是非常消耗时间的
有没有办法能减少网络请求呢?答案就是缓存
缓存位置
首先要了解一下缓存保存在哪里,浏览器又是如何索引缓存的
按照访问顺序,缓存一般有如下 4 个存储位置
- Service Worker
- Memory Cache
- Disk Cache
- Push Cache
Service Worker
Service Worker 是运行在浏览器背后的独立线程,一般可以用来实现缓存功能
使用 Service Worker 的话,传输协议必须为 HTTPS,因为 Service Worker 中涉及到请求拦截,所以必须使用 HTTPS 协议来保障安全
Service Worker 的缓存与浏览器其他内建的缓存机制不同,它可以让我们自由控制缓存哪些文件、如何匹配缓存、如何读取缓存,并且缓存是持续性的
Memory Cache
也就是内存缓存,包含一些小文件
但一旦关掉当前标签页,该标签页对应的内存缓存就被释放了
Disk Cache
硬盘缓存,显然比内存缓存要慢,但存储空间要大,且只有资源过期了才会释放资源
一般大文件会放到 Disk Cache 中,小文件放到 Memory Cache 中
但如果当前系统内存占用高,则会优先存进 Disk Cache
Push Cache
是 HTTP 2 中的 服务端推送 产生的缓存,只在 session 中存在,且缓存时间也很短(在 Chrome 中约 5 分钟)
关于其优点,详见 HTTP 2 的特点描述
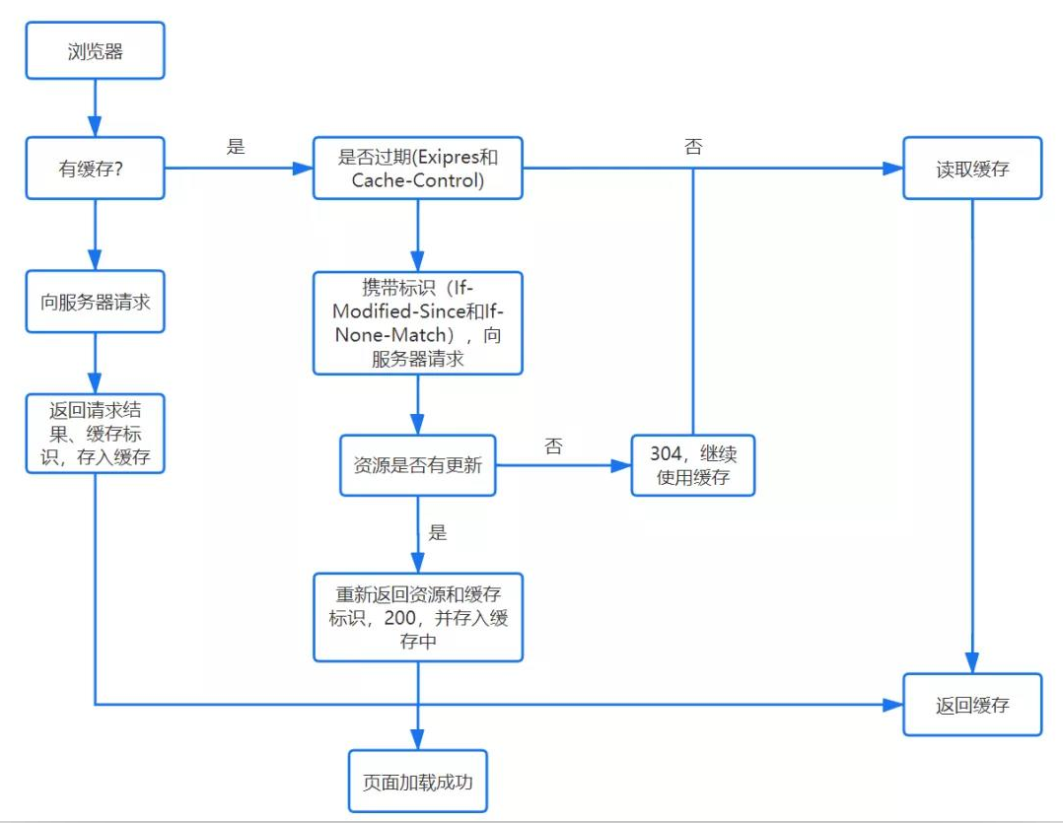
缓存过程
浏览器会根据以下流程,确定缓存的处理方法
URL 解析后,是否含有目标地址的缓存?
否
- 向服务器发送请求
- 返回请求结果和缓存标识,将结果存入缓存
是
缓存是否过期?
根据 Expires ( HTTP 1.0 ) 或 Cache-Control ( HTTP 1.1 ) 判断
- 是(协商缓存机制)
- 在头部添加字段 If-Modified-Since ( HTTP 1.0 ) 或 If-None-Match ( HTTP 1.1 ) ,然后向服务器发送请求
- 服务器根据字段值判断资源是否有更新,并响应给浏览器
- 资源是否更新?
- 是,则连带 HTML 文档一同返回给浏览器,同时状态码置为 200,浏览器将请求结果存入缓存
- 否,返回状态码 304,读取并返回缓存
- 否(强缓存机制)
- 读取并返回缓存
- 是(协商缓存机制)
缓存机制图示如下
强缓存
缓存未过期,则不会向服务器发送请求,直接读取并返回缓存
该操作会在控制台产生一个假请求,返回状态码 200,并显示 from memory cache 或 from disk cache
由上图可见,有两个参数可以决定强缓存
- Expires
- Cache-Control
Expires
是 HTTP 1 的产物
由服务端指定具体多久之后过期,关键字段名为 max-age,实际的 Expires = max-age + 服务器收到请求的时间
显然,Expires 是否过期,取决于与本地时间的对比结果,所以如果设置本地时间为超过 Expires 的值,则会直接造成 Expires 过期
Cache-Control
是 HTTP 1.1 的产物
一般有以下字段
| 字段名 | 参考值 | 作用 |
|---|---|---|
| public | 无 | 客户端和代理服务器均可以缓存该资源 |
| private | 无 | 只有客户端可以缓存该资源 |
| max-age | 30 | 缓存 30 秒后过期 |
| s-maxage | 30 | 覆盖 max-age,但只在代理服务器中生效 |
| no-store | 无 | 不缓存 |
| no-cache | 无 | 资源被缓存,但立即过期,下次请求会发起协商缓存认证 |
| max-stale | 30 | 30 秒内即使过期也使用该缓存 |
| min-fresh | 30 | 希望在 30 秒内获取最新的响应 |
推荐的配置思路图如下
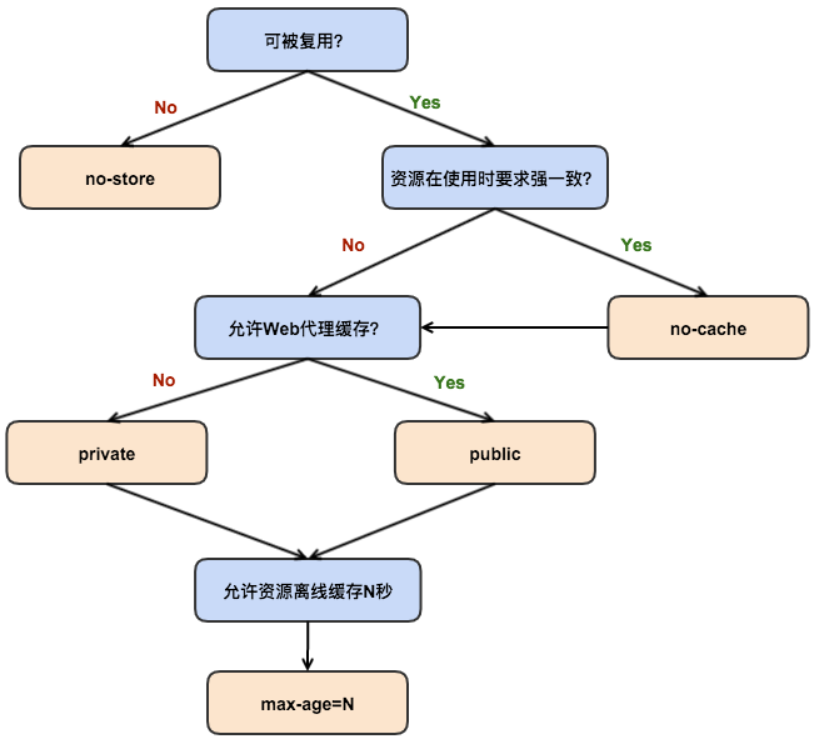
在使用 Cache-Control 的时候,有两种常见情况,其描述和对策如下
| 情况 | 对策 | 描述 |
|---|---|---|
| 资源频繁更新 | Cache-Control: no-cache | 永不缓存,确保时效性 |
| 资源不常更新 | Cache-Control: max-age=31536000 | 缓存一年 |
对比
由上文可知,Cache-Control 是更新版本的参数,也具有更强大的功能,所以当 Cache-Control 和 Expires 同时存在时,Cache-Control 优先级要高于 Expires
现在的 Expires,只是为了兼容不支持 HTTP 1.1 的环境罢了
协商缓存
当强缓存查找不到未过期的合适缓存,但存在已过期的合适缓存时,浏览器会采用协商缓存策略
一般有两种情况
- 协商缓存有效,服务器返回 304 Not Modified
- 协商缓存失效,服务器返回 200 和新的资源
那么如何提交协商缓存请求呢?可以通过设置两组参数实现
Last-Modified 和 If-Modified-Since
是 HTTP 1 提出的缓存控制参数
浏览器在第一次访问资源时,服务器可以在响应中加入请求头 Last-Modified,值是这个资源在服务器上的最后修改时间
浏览器下次强缓存命中失败,要请求这个资源时,发现这个已过期资源带有 Last-Modified 标识,则会在请求中带上 If-Modified-Since 的 header
服务器收到 If-Modified-Since 后,与服务器上的资源对比,如果 If-Modified-Since 的时间小于服务器上该资源的最后更新时间,则说明资源有更新,服务器返回 200 和新的资源文件,否则仅返回 304
但如果客户在本地打开缓存文件,即使没有修改,也依然会造成 Last-Modified 更新,此时会导致缓存失效
并且,Last-Modified 的精确度是秒,所以如果在小于秒的时间内修改了文件,Last-Modified 并不会更新,导致命中的文件不正确
所以,HTTP 1.1 提出了更加精确的验证参数,Etag 和 If-None-Match
Etag 和 If-None-Match
浏览器在第一次访问资源时,服务器可以在响应中加入请求头 Etag,值是这个资源在服务器上的唯一标识。只要文件发生变化,Etag 就会重新生成
如同 Last-Modified,浏览器在使用 Etag 进行协商缓存时,也会在请求中加入特殊的 header,此时这个 header 为 If-None-Match
如果 If-None-Match 与服务器上的文件标识符相同,则返回 304,否则返回 200 和新的资源文件
对比
显然 Etag 要比 Last-Modified 更精确,但精确的代价就是生成标识符的算法的复杂性增大
但大部分情况下,Etag 造成的性能损耗都可以忽略不计,所以当 Etag 和 Last-Modified 同时存在时,Etag 的优先级较高
无缓存策略
如果服务器什么缓存都没设置,难道就不缓存了吗?显然不是
此时浏览器会取响应报文中的 Date 来减去 Last-Modified,取得一个时间差值,然后取这个差值的 10% 作为缓存时间
DNS 查询
DNS 查询流程按顺序一般如下
- 浏览器缓存
- 操作系统缓存
- 路由器缓存
- 主机上的 hosts 文件
- 本地域名服务器等域名服务器
TCP 连接
流程中说到,浏览器与服务器之间会建立 TCP 连接来传输数据,那么显然具有至少一个 TCP 连接
那么自然产生了以下问题
- 一个 TCP 连接能用多久?什么时候断开?
- 一个 TCP 连接可以承担几个 HTTP 请求的任务?
- 一个 TCP 连接能不能同时发送数个 HTTP 请求?
- 浏览器最多能对同一服务器建立几个 TCP 连接?
一个 TCP 连接能用多久
在 HTTP 1 中,服务器会在响应了一个 HTTP 请求后,立刻断开这个 TCP 连接
但如果要对该服务器连续发起多个请求,重复建立连接显然开销过大
于是开始有某些服务器,提出了不在 HTTP 标准中的头部字段 Connection,并通过设置 Connection: keep-alive 来保持当前请求使用的 TCP 连接不断开
因为 SSL 也是基于 TCP 的,所以此时 SSL 连接也不会断开,不需要重新交换密钥和验证
既然 Connection: keep-alive 这么好用,于是 HTTP 1.1 就将其加入了标准之中,并且默认保持 TCP 连接,除非手动在请求头中指定 Connection: close
一个 TCP 连接可以承担几个 HTTP 请求的任务
从上一个问题,显然可以看出,如果一个 TCP 连接不断开,是可以用来发送多个 HTTP 请求的,直到断开为止
一个 TCP 连接能不能同时发送数个 HTTP 请求
在 HTTP 1.1 中,一个 TCP 连接同时只能处理一个请求,不同请求不能同时使用同一个 TCP 连接
虽然标准中设计了一个参数 Pipelining 来试图解决这个问题,但是了解网络工作原理的人都知道,客户端按某个顺序发送的请求,服务器并不能按顺序接收(同一个请求的 IP 报文可以,详见 IP 数据报)
那就造成客户端发送请求后,接收到的响应不能和请求按发送时的顺序一一对应,那请求就完全错乱了
所以在 HTTP 1.x 的场合,浏览器没有合适的并发方案,只能通过保持连接或同时并行多个连接来提高效率
但是 HTTP 2 中引入了多路复用的概念,在应用层采取如同网络层的 IP 数据报一样的分段标号模式,此时同一个 TCP 连接就可以正常并发多个 HTTP 请求了
浏览器最多能对同一服务器建立几个 TCP 连接
依据浏览器不同,这个限制是不同的
对于 Chrome,最多允许对同一个 host 建立 6 个 TCP 连接
HTTP 与 HTTPS
HTTP 1.0 和 HTTP 1.1 在上文已经有提到一些了,除了缓存机制和 TCP 以外也没有什么太大的差别,所以着重讨论 HTTP 2.0 和 HTTPS
HTTP 2.0
HTTP 2.0 有如下特点
- 二进制分帧
- 首部压缩
- 多路复用
- 服务端推送
二进制分帧
我们知道数据链路层有以太网帧,网络层有 IP 报文分割,此处的二进制分帧设计思路正是基于前两者的特点而得来的
使用了二进制分帧后,每个 HTTP 报文都使用二进制格式传输数据,每个报文都由一个或多个帧组成
相比 HTTP 1.x 的文本格式传输,HTTP 2.0 的二进制格式解析效率更高
为了正常使用帧,HTTP 2.0 同时使用了流的概念
流是一个虚拟通道,可以承载双向消息,每个流都有一个唯一 ID
简单理解,流就是同一组请求和响应的组号
首部压缩
显然每个请求之间都使用了大量的头部字段,且这些字段的值在浏览器和服务器之前是一致的
HTTP 2.0 则采用了”首部表”来缓存已经发送过的头部字段键值对,使得浏览器和服务器对于与缓存相同的字段,不需要重复在请求中发送,显著减小了请求报文的大小
该首部表在 HTTP 2.0 连接断开前始终存在,由使用双方共同更新
当产生未记录的键值对时,要么更新首部表中的记录值,要么追加到首部表的末端
多路复用
在 HTTP 2.0 中,相同域名下的所有通信都使用同一个连接完成,该连接可以并发任意数量的请求和响应,克服了 HTTP 1.x 中同一个连接不能并发请求的问题,消除了 TCP 连接多次建立以及浏览器同时维护多个 TCP 连接的开销
之所以可以做到这一点,是因为二进制分帧后,同一个流的每个帧都含有首部流标识,可以乱序发送,双方都可以根据首部流标识得到正确的消息
该设计思路的具体描述可以参考 IP 数据报的分割
服务端推送
是 HTTP 2.0 最重要的特性
在 HTTP 1.x 中,如果浏览器没有发出请求,服务器是不能向浏览器发送数据的
但在 HTTP 2.0 中,服务器可以打开 PUSH 模式,当浏览器请求了一个资源后,服务器可以推送相关资源给浏览器
例如,有如下 HTML
1 | <html> |
如果在 HTTP 1.x 中,浏览器需要发起 3 个请求,才可以得到整个页面的完整数据
但在 HTTP 2.0 中,如果服务器打开 了 PUSH 模式,浏览器只需要发送 1 个请求,申请取得 HTML 文档,服务器就会先返回 HTML 文档,然后根据 HTML 文档中的资源指向,向浏览器推送 css 文件和 png 文件,这样浏览器在后续要使用的时候,就发现已经收到了资源,不需要再发请求了
这样,只要 1 个请求,就完成了以前 3 个请求才能完成的事情,效率显然大大提高
既然服务器可以主动推送,客户端自然也可以选择是否接受
如果服务端推送的资源已经被浏览器缓存过,浏览器可以通过发送RST_STREAM帧来拒收
主动推送也遵守同源策略,服务器不会随便推送第三方资源给客户端。
HTTPS
HTTPS 基于 SSL 协议,采用 RSA 算法,使得通信双方不需要直接发送私钥,就可以达成合意开始加密通信
具体流程如下
- 浏览器向服务器发起 HTTPS 连接请求
- 服务器向浏览器发送公钥和根据自己的私钥与公钥联合加密的密文
- 浏览器收到公钥和密文,随机产生一个私钥,向服务器发送根据自己的私钥与公钥联合加密的密文
- 双方都根据公钥、自己的私钥和对方发送的密文进行计算,得到共同的密钥,通信建立
- 在之后的通信中,都使用这个计算出来的密钥进行加密通信
算法原理概述可以参看 图解非对称加密
页面渲染
首先是浏览器渲染 5 步图

根据上图,可知浏览器渲染流程如下
首次渲染
- 解析 JS 脚本。该动作会导致阻塞,所以一般放在 HTML 文档最后
- 构建 DOM 树和 CSSOM 树
- 合并为渲染树,进行布局
- 布局完成后,根据渲染树进行绘制
- 绘制完成后交由 GPU 进行合成
后续渲染
- 解析 JS 脚本
- 计算布局和样式更改
- 将布局和样式更改同步到渲染树上
- 根据渲染树重排、重绘
- 重绘完成后交由 GPU 进行合成
特性
浏览器渲染有如下几个特性
容错机制
我们在编码中从来没有见过浏览器报 HTML 和 CSS 的错,因为现代浏览器对 CSS 有强大的容错能力,会自动修复那些可以修复的 HTML 和 CSS 的语法错误,对于不能修复的则直接跳过不加解析
页面生命周期
HTML 页面生命周期中有以下事件
- DOMContentLoaded
- load
- beforeunload
- unload
触发时间点如下
| 事件 | 触发时点 |
|---|---|
| DOMContentLoaded | 当 DOM 树构建完毕 |
| load | 当所有资源已经加载完毕 |
| beforeunload | 当用户正在离开页面,此时数据尚未清除 |
| unload | 当用户已经离开页面 |
通常我们可以利用 beforeunload 事件来弹出一个对话框,用以询问用户是否确定离开
需要注意的是,当 DOMContentLoaded 事件发生时,async 和 defer 脚本可能尚未执行,其余文件也很有可能正在下载中,不要轻易访问它们
除了上述事件,我们也可以用 document.readyState 来获取页面当前的状态,并通过 readystatechange 事件来监听页面生命周期的变化
document.readyState 通常有 3 个值
- loading,页面正在加载中
- interactive,页面解析完毕,触发时点与 DOMContentLoaded 相同,但执行时比 DOMContentLoaded 要早
- complete,页面上所有资源都已经加载完毕,触发时点与 load 相同,但执行时比 load 要早